
大约一年前,Semrush开始深入研究反向链接,并设定目标:为自己的客户建立当前市场上最大、更新速度最快、质量最高的反向链接数据库,并优于市场上其它所有知名竞争对手。为此:
- 整个团队工作 18 个月
- 30,000 个专家工程小时
- 完全迁移到新架构(所有 43.8 万亿已知历史数据链接保存)
- 500多个服务器
- 16,128 个 CPU 内核
- 用于运算的 245 TB 内存
- 13.9 PB 的空间用于存储链接数据库
- 还有16,722 杯咖啡
下图为Semrush反向链接分析数据库,目前一直在增长
- 反向链接:43 兆/万亿
- 引荐域名/引用域名:16亿
- 每日爬行URL数量:250亿

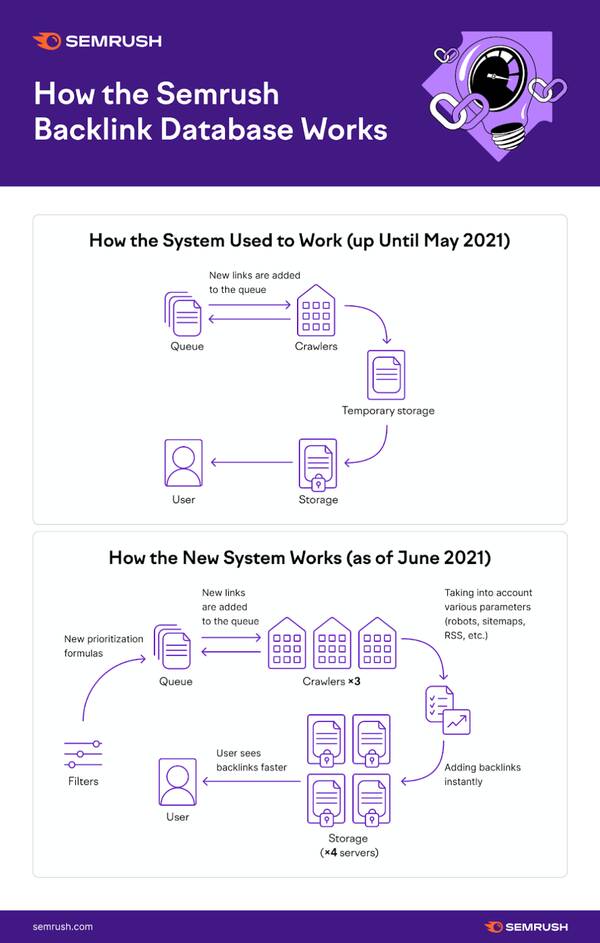
Semrush 反向链接数据库的工作原理
首先,生成一个 URL 队列,决定爬行和抓取哪些页面。
其次,爬虫检查这些页面。当爬虫识别出从这些页面指向 Internet 上另一个页面的超链接时,保存该信息。
然后,将所有这些数据临时保存,之后将其转储到Semrush库中,这样所有Semrush用户都可以在自己的界面中看到这些数据。
为此,基本上删除了所有临时存储的步骤,增加了 3 倍的爬虫,并在队列前添加了一组过滤器,因此整个过程更快、更高效。 整个过程如下图所示:
过去
- 队列
- 将新链接添加至队列
- 爬虫
- 临时存储
- 存储
- 反馈给Semrush用户
现在
- 初期过滤
- 确定优先级
- 队列
- 将新链接添加至队列
- 3倍数量爬虫(相比原来)
- 考虑到各种参数(机器人、站点地图、RSS 等)
- 即刻添加反向链接
- 4倍服务器存储(相比原来)
- Semrush用户迅速看到这些反向链接
队列
互联网有无穷无尽的页面,好多页面都要抓取,但并不是全部抓取。
有些抓取要频繁,有些则根本不需要抓取。因此,要使用一个队列来决定 URL 将按什么顺序提交以供抓取。
问题是:如果抓取太多相似、不相关的 URL,这样,一方面会导致spam增多,但是另一方面,引用域名会减少。
措施:
优化抓取队列:添加了过滤器,优先考虑独特的内容、更高权限的网站,并防止链接农场。
因此,增加了独特内容页面,减少了具有重复链接的报告。
部分亮点:
- 为了保护队列免受链接群的影响,检查是否有大量域名来自同一 IP 地址。
如果来自同一个 IP 的域名太多,则降低优先级。这样,就能从不同的 IP 抓取更多的域名。 - 检查来自同一域名的 URL 是否过多。
如果在同一个域名中有过多的 URL,不会在同一天全部被抓取。 - 为确保尽快抓取新页面,之前未抓取的任何 URL 将具有更高的优先级。
- 每个页面都有自己的哈希码,可帮助优先抓取独特的内容。
- 考虑在源页面上生成新链接的频率。
- 考虑网页和域名的权威评分。
改进队列:
- 10 多个不同的因素来过滤掉不必要的链接。
- 由于质量控制的新算法,获取更多独特和高质量的页面。

爬虫
爬虫跟踪 Internet 上的内部和外部链接,以搜索带有链接的新页面。因此,如果有传入链接(incoming link)的话, 只找一个页面 。
措施
- 爬虫数量增加了三倍(从 10 到 30)。
- 停止抓取带有不影响页面内容(&sessionid、UTM 等)的 url 参数的页面。
- 增加阅读和遵守网站上 robots.txt 文件说明的频率。
改进爬虫:
- 更多爬虫(现在 30 个)
- 清理数据,没有垃圾或重复链接
- 更善于找到最相关的内容
- 每天250亿页的爬行速度
存储
存储是 Semrush将这些所有的链接数据存储下来,供其免费/付费用户查阅。 给用户可以看到的所有链接的地方。
因为爬虫爬网是一个持续不断的过程,得到新数据之后,数据库要重新更新,这个过程大概是2-3个星期。一般情况下,在更新过程中,用户使用此工具那就会出现延迟,那么要解决这个问题-即提升速度。
措施
为了改善这一点,Semrush从头开始重写了架构。为了解决存储需求,将服务器数量增加了四倍,其专家又花费了3万多个工时,现在,这个反向链接数据库系统,不受任何限制了。
改进存储:
- 500+ 台服务器
- 287TB RAM 内存
- 16,128 个 CPU 内核
- 30 PB 总存储空间
- 闪电般的过滤和报告
- 即时更新 – 不再有临时存储
Semrush免费帐户即可获得访问权限,反向链接分析功能完全开放。